
スクレイピングで、ASINから、情報を取得。サンプルファイルDL可能。
以下のシートを例にマクロを紹介します。

A列のASINから情報(タイトル・発行年・出版社・著者・ページ数・ランキング)を取得するマクロです。Webブラウザ(Edge/Chrome)の自動操作のために、Seleniumを使用しています。ブラウザはEdgeを使用しています。以下がマクロの全体です。
Option Explicit
' 列挙型で列番号を指定
Enum clm
ASIN = 1
タイトル列
発行年列
出版社列
著者列
ページ数列
ランキング列
End Enum
Dim driver As Selenium.WebDriver
Dim htmlDoc As HTMLDocument
Dim ランキング As Long
Dim タイトル As String
Dim 出版社 As String
Dim 発行年 As String
Dim ページ数 As String
Dim 著者 As String
Sub main()
Dim ws As Worksheet
Set ws = ThisWorkbook.Worksheets("01")
Dim LastRw As Long
LastRw = ws.Cells(Rows.Count, 1).End(xlUp).Row
Dim rw As Long
For rw = 2 To LastRw
' 変数の初期値設定
ランキング = 0
タイトル = ""
出版社 = ""
発行年 = ""
ページ数 = ""
著者 = ""
Call ASINから情報を取得(ws.Cells(rw, clm.ASIN))
ws.Cells(rw, clm.ランキング列) = ランキング
ws.Cells(rw, clm.タイトル列) = タイトル
ws.Cells(rw, clm.出版社列) = 出版社
ws.Cells(rw, clm.発行年列) = 発行年
ws.Cells(rw, clm.ページ数列) = ページ数
ws.Cells(rw, clm.著者列) = 著者
Next rw
End Sub
' ASINから
Sub ASINから情報を取得(ByVal ASIN As String)
Set driver = New Selenium.WebDriver
' Edgeを開く
driver.Start "edge"
'ASINから作成したURL
Dim URL As String
URL = "https://www.amazon.co.jp/o/asin/"
URL = URL & ASIN & "/"
' URLを開く
driver.Get URL
'■ブラウザ読み込み待ち(ページロード待ち)する
driver.Wait 500 '0.5秒待つ。
'「HTMLDocument」のオブジェクトで「htmlDoc」を宣言し(この時点ではhtmlDocはただの箱)、Newする』ことで、「HTMLDocument」の構造を「htmlDoc」にセットしインスタント化する。
' 「htmlDoc」にある「body」内の「innerHTML」に「driver.PageSource」を貼り付ける。
Set htmlDoc = New HTMLDocument
htmlDoc.body.innerHTML = driver.PageSource
' ランキングを、正規表現を使用して、取得
ランキング = ランキング_from_HTML(driver.PageSource)
' 指定のCSSセレクタのデータをすべて取得
Dim els
Dim m As Long
' タイトルを取得。
Set els = htmlDoc.querySelectorAll("#productTitle")
If els Is Nothing Then
MsgBox "「タイトル」の要素が見つかりません"
Else
' 前後の空白行を削除
タイトル = Trim(els(0).innerText)
End If
'出版社、発行年、ページ数を取得するため、「登録情報」を取得
Dim 登録情報arr(0 To 10) As Variant
Set els = htmlDoc.querySelectorAll("#detailBullets_feature_div > ul > li > span > span")
If els Is Nothing Then
MsgBox "「登録情報」の 要素が見つかりません"
Else
For m = 0 To 10
If els(m) Is Nothing Then Exit For
登録情報arr(m) = els(m).innerText
Next m
End If
' 登録情報から出版社・発行年・ページ数を取得。
For m = 0 To UBound(登録情報arr)
' 出版社があれば、次の項目を取得
' If InStr(登録情報arr(m), "出版社") > 0 Then
' '二見書房 (1978/1/1) を分割
' Dim var As Variant
' var = Split(登録情報arr(m + 1), " (")
' 出版社 = var(0)
'
' '1978/1/1) を分割
' var = Split(var(1), "/")
' If IsNumeric(var(0)) = True Then
' 発行年 = var(0)
' End If
' End If
' 以下に変更になったので、変更。20260613
'登録情報arr(0):出版社 ? : ?
'登録情報arr (1): 大修館書店
'登録情報arr(2):発売日 ? : ?
'登録情報arr(3):1995/4/1
'登録情報arr(4):言語 ? : ?
'登録情報arr (5): 日本語
'登録情報arr(6):本の長さ ? : ?
'登録情報arr(7):210ページ
Select Case True
Case InStr(登録情報arr(m), "出版社") > 0
If m + 1 <= UBound(登録情報arr) Then
出版社 = 登録情報arr(m + 1)
End If
Case InStr(登録情報arr(m), "発売日") > 0
If m + 1 <= UBound(登録情報arr) Then
If IsDate(登録情報arr(m + 1)) Then
発行年 = Year(CDate(登録情報arr(m + 1)))
End If
End If
End Select
' Debug.Print "登録情報arr(" & m; "):" & 登録情報arr(m)
If InStr(登録情報arr(m), "ページ") > 0 Then
Dim PageTxt As String
PageTxt = Replace(登録情報arr(m), "ページ", "")
If IsNumeric(PageTxt) = True Then
ページ数 = PageTxt
End If
End If
Next m
If ページ数 = "" Then ページ数 = "なし"
' 著者を取得
Dim 著者arr(0 To 10) As Variant
Set els = htmlDoc.querySelectorAll("#bylineInfo")
If els Is Nothing Then
MsgBox "要素が見つかりません"
Else
For m = 0 To 10
If els(m) Is Nothing Then Exit For
著者arr(m) = els(m).innerText
Next m
End If
' 著者 = Trim(著者arr(0))
' 以下に変更になったので、変更。20260613
' 著者arr(0) : "遠藤 瓔子 (著) 形式: 大型本 "
著者 = Trim(Split(Trim(著者arr(0)), "形式")(0))
' ブラウザを閉じる
driver.Close
End Sub
Function ランキング_from_HTML(ByVal URL As String) As Long
Dim re As Object
Dim mc As Object
Dim msg As String
Dim i As Long
'RegExpオブジェクトを作成する
Set re = CreateObject("VBScript.RegExp")
With re
'正規表現パターンを設定する
' https://www.megasoft.co.jp/mifes/seiki/s012.html
' - 164,994位本
.Pattern = "[-]\s\b\d{1,3}(,\d{3})*\b[位]"
'複数マッチを有効にする
.Global = True
'文字列「ExcelVBA PoerPoint AccessVBA」に対して実行する
Set mc = .Execute(URL)
End With
'結果に対して処理を行う
With mc
'対象文字列が見つかったかどうか判定する
If .Count > 0 Then
'見つかった場合、文字列を取得する
msg = .Item(i).Value
Else
'見つからなかった場合の文字列
msg = ""
End If
End With
'MsgBox msg
msg = Replace(Replace(Replace(msg, "-", ""), "位", ""), ",", "")
ランキング_from_HTML = CLng(Val(msg))
End Function2026年6月、マクロがエラーで停止するので、以下改造しました。
' 登録情報から出版社・発行年・ページ数を取得。
For m = 0 To UBound(登録情報arr)
' 出版社があれば、次の項目を取得
' If InStr(登録情報arr(m), "出版社") > 0 Then
' '二見書房 (1978/1/1) を分割
' Dim var As Variant
' var = Split(登録情報arr(m + 1), " (")
' 出版社 = var(0)
'
' '1978/1/1) を分割
' var = Split(var(1), "/")
' If IsNumeric(var(0)) = True Then
' 発行年 = var(0)
' End If
' End If
' 以下に変更になったので、変更。20260613
'登録情報arr(0):出版社 ? : ?
'登録情報arr (1): 大修館書店
'登録情報arr(2):発売日 ? : ?
'登録情報arr(3):1995/4/1
'登録情報arr(4):言語 ? : ?
'登録情報arr (5): 日本語
'登録情報arr(6):本の長さ ? : ?
'登録情報arr(7):210ページ
Select Case True
Case InStr(登録情報arr(m), "出版社") > 0
If m + 1 <= UBound(登録情報arr) Then
出版社 = 登録情報arr(m + 1)
End If
Case InStr(登録情報arr(m), "発売日") > 0
If m + 1 <= UBound(登録情報arr) Then
If IsDate(登録情報arr(m + 1)) Then
発行年 = Year(CDate(登録情報arr(m + 1)))
End If
End If
End Select
' Debug.Print "登録情報arr(" & m; "):" & 登録情報arr(m)
If InStr(登録情報arr(m), "ページ") > 0 Then
Dim PageTxt As String
PageTxt = Replace(登録情報arr(m), "ページ", "")
If IsNumeric(PageTxt) = True Then
ページ数 = PageTxt
End If
End If
Next m
If ページ数 = "" Then ページ数 = "なし"
' 著者を取得
Dim 著者arr(0 To 10) As Variant
Set els = htmlDoc.querySelectorAll("#bylineInfo")
If els Is Nothing Then
MsgBox "要素が見つかりません"
Else
For m = 0 To 10
If els(m) Is Nothing Then Exit For
著者arr(m) = els(m).innerText
Next m
End If
' 著者 = Trim(著者arr(0))
' 以下に変更になったので、変更。20260613
' 著者arr(0) : "遠藤 瓔子 (著) 形式: 大型本 "
著者 = Trim(Split(Trim(著者arr(0)), "形式")(0))変更点①:出版社・発行年の取得方法を新しいサイト形式に対応
従来は、出版社名と発行日が1つの文字列にまとめて表示されていました。
二見書房 (1978/1/1)そのため、以下のように Split 関数で出版社名と発行日を分割して取得していました。var = Split(登録情報arr(m + 1), " (")
出版社 = var(0)しかし、サイトの仕様変更により、現在は出版社と発売日が別々の項目として取得されるようになりました。出版社 ? : ?
大修館書店
発売日 ? : ?
1995/4/1そのため、出版社と発売日をそれぞれ個別に検索する方式へ変更しました。Select Case True
Case InStr(登録情報arr(m), "出版社") > 0
出版社 = 登録情報arr(m + 1)
Case InStr(登録情報arr(m), "発売日") > 0
発行年 = Year(CDate(登録情報arr(m + 1)))
End Selectまた、If m + 1 <= UBound(登録情報arr) Thenによる配列範囲チェックと、If IsDate(登録情報arr(m + 1)) Thenによる日付判定を追加したことで、データ形式の変更によるエラーが発生しにくい、より堅牢な処理になりました。変更点②:著者名の取得方法を新しい表示形式に対応
従来は、著者情報がシンプルな形式で取得できたため、先頭要素をそのまま著者名として使用していました。
著者 = Trim(著者arr(0))しかし、現在は著者名の後ろに書籍形式が付加されるようになっています。遠藤 瓔子 (著) 形式: 大型本このまま取得すると、著者名だけでなく「形式: 大型本」まで含まれてしまいます。そこで、
著者 = Trim(Split(Trim(著者arr(0)), "形式")(0))へ変更し、「形式」という文字列で分割して前半部分のみを取得するようにしました。処理後は、
遠藤 瓔子 (著)
のみが取得されるため、従来どおり著者情報だけを保存できます。この修正により、サイト側で書籍形式の表示が追加されても、不要な文字列を除外して正しい著者名を取得できるようになりました。
サイト仕様変更により取得データの構造が変わったため、文字列分割方式から「項目名を検索して値を取得する方式」へ変更し、さらにエラーチェックを追加することで、将来的なレイアウト変更にも対応しやすいマクロへ改善しました。
以下が実行した結果です。
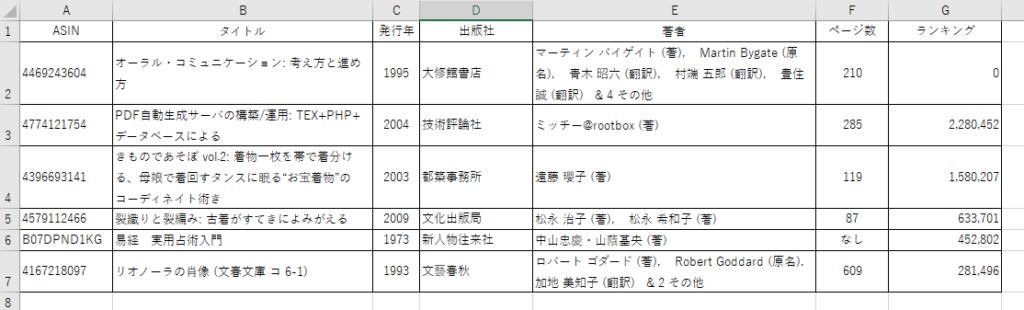
サンプルのマクロブックは、以下から、ダウンロードしてください。
初心者向けに、SeleniumBasic+WebDriver導入手順をまとめました。
サンプルのマクロブックが動作しない場合は、WebDriverとEdgeのバージョンが違う可能性があるので、以下を確認してください。
こちらは簡易版です。Seleniumを使用するための、事前準備は、以下を参照してください。WebDriverの自動更新に関する記事もあります。
Follow me!

